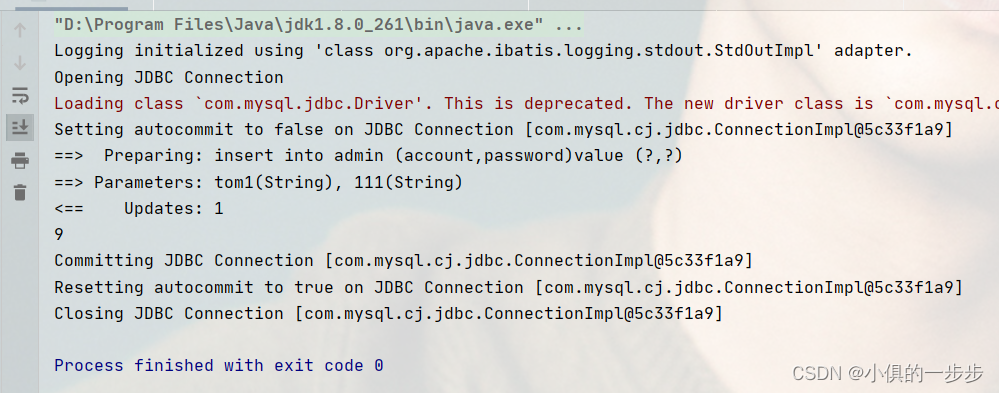
延迟应答
为什么有延迟应答
发送方如果长时间没有收到ACK应答,则会触发超时重传机制,重新发送数据包。但如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小,发送方一次只能发少量数据,效率较低。
举个例子理解一下
假设接收端缓冲区为1M. 一次收到了500K的数据; 如果立刻应答, 返回的窗口就是500K;
但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;
在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大一些, 也能处理过来;
如果接收端稍微等一会再应答, 比如等待200ms再应答, 那么这个时候返回的窗口大小就是1M;
在可靠性和性能间做平衡
窗口越大, 意味着网络吞吐量就越大, 传输效率就越高,数据包越多,丢包可能性越大。我们的目标是在保证网络不拥塞的情况下尽量提高传输效率;
注意:该机制依具体实现而定,不统一
- 数量限制: 每隔N个包就应答一次;
- 时间限制: 超过最大延迟时间就应答一次;
- 具体的数量和超时时间, 依操作系统不同也有差异; 一般N取2, 超时时间取200ms;
滑动窗口
看这篇 滑动窗口
快速重传
快速重传是对TCP发送方降低等待重发丢失分段用时的一种改进。
理解一下
想象一下,当你通过互联网发送消息给朋友,如果某个消息没有被朋友收到,你希望朋友能够提醒你重发,而不是等到整个通信结束再告诉你。
快速重传机制的工作方式类似于这个想法。当发送方向接收方发送数据时,接收方会在接收到数据后,发送一个“确认”的信号给发送方,告诉发送方已经收到了数据。但是有时候,这个确认信号可能会在传输过程中丢失,导致发送方认为数据没有被接收到。
为了解决这个问题,快速重传机制会让接收方不只是等待一个确认信号,而是在接收到部分数据后就开始发送确认信号。如果接收方发现某个数据包丢失,它会立即告诉发送方,让发送方重发这个数据包,而不必等待更多的数据传输完成。
通过什么实现的呢
通过ACK确认应答机制
TCP发送方每发送一个分段都会启动一个超时计时器,如果没能在特定时间内接收到相应分段的确认,发送方就假设这个分段在网络上丢失了,需要重发。这也是 TCP 用来估计 RTT 的测量方法。这个机制就是超时重传机制。
重复确认就是这个阶段的基础,其基于以下过程:如果接收方接收到一个数据分段,就会将该分段的序列号加上数据字节长的值,作为分段确认的确认号,发送回发送方,表示期望发送方发送下一个序列号的分段——>但是如果接收方提前收到更下一个序列号的分段或者说接收到无序到达的分段,即之前期望确认号对应的分段出现接收丢失——>接收方需要立即使用之前的确认号发送分段确认——>此时如果发送方收到接收方相同确认号的分段确认超过1次,并且该对应序列号的分段超时计时器仍没超时的话,则这就是出现重复确认,需要进入快速重传。
快速重传就是基于以下机制:我们假设重复阈值为3,当发送方收到4次相同确认号的分段确认(第1次收到确认期望序列号,加3次重复的期望序列号确认)时,则可以认为继续发送更高序列号的分段将会被接受方丢弃,而且会无法有序送达。发送方应该忽略超时计时器的等待重发,立即重发重复分段确认中确认号对应序列号的分段。
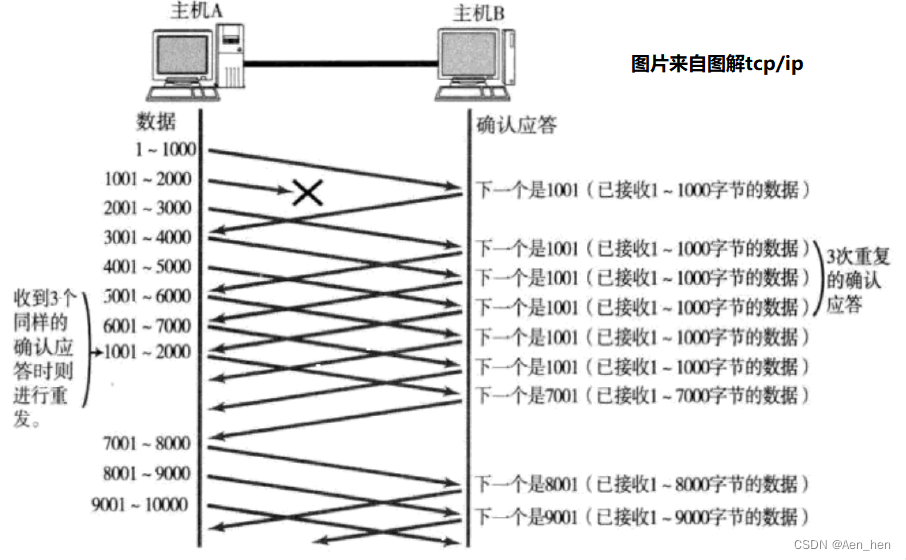
连续3个以上收到了同样的应答,才会触发快重传的机制。因为3次作为触发快速重传的标准是经验得出的一个相对平衡的值。
如图:
- 当某一段报文段丢失之后, 发送端会一直收到 1001 这样的ACK, 就像是在提醒发送端 "我想要的是 1001"一样;
- 如果发送端主机连续三次收到了同样一个 “1001” 这样的应答, 就会将对应的数据 1001 - 2000 重新发送;
- 这个时候接收端收到了 1001 之后, 再次返回的ACK就是7001了(因为2001 - 7000)接收端其实之前就已经收到了, 被放到了接收端操作系统内核的接收缓冲区中;
捎带应答
捎带应答机制是一种让网络通信更高效的方法。在生活中就像军队里用的无线电对讲机类似,我说一句话,你回收到,同时跟我讲你想跟我说的话。
捎带应答机制在网络通信中就是这个概念。当一台计算机发送数据给另一台计算机时,接收方在回复的数据中会附上一个确认信号,表示它已经收到了之前发送的数据。这个确认信号被“捎带”在回复的数据中,就像朋友的回复带上了对你的消息的确认一样。
这样做的好处是,发送方不需要额外等待确认信号,因为它已经包含在回复中了。这样可以节省时间和网络带宽,使通信更高效。