首先,用
n
\rm n
n 表示
S
\rm S
S 串的长度,用
m
\rm m
m 表示
w
o
r
d
s
\rm words
words 的长度即words中单词的数量,用
w
\rm w
w 表示
w
o
r
d
s
\rm words
words 中每个单词的长度。
①对于
S
\rm S
S 串以
w
\rm w
w 为长度进行分割,则每一个
w
\rm w
w 独立存在(可看成一个元素)。
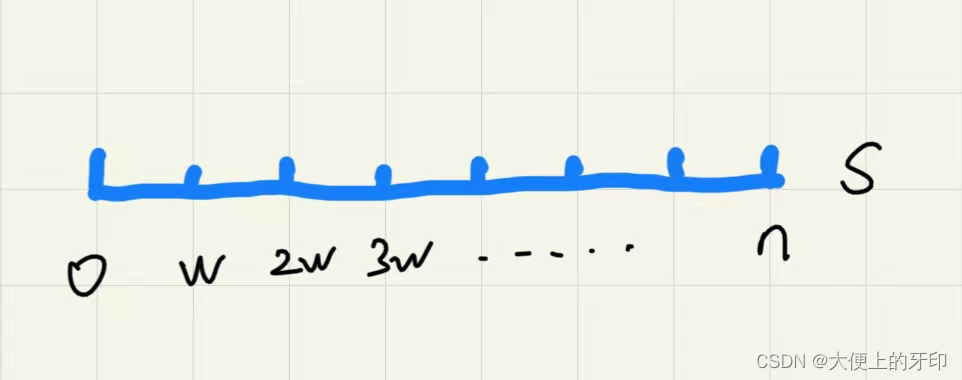
②则有以
i
=
0
,
1
,
…
,
w
−
1
i = 0,1,\dots,w-1
i=0,1,…,w−1 的
w
\rm w
w 起点,看作
w
\rm w
w 个组。
③在该串上,对每一个长度为
w
\rm w
w 看作独立存在的元素,维护一个长度为
m
\rm m
m 的滑动窗口,
j
\rm j
j 作为滑动窗口的结尾,用来维护长度。
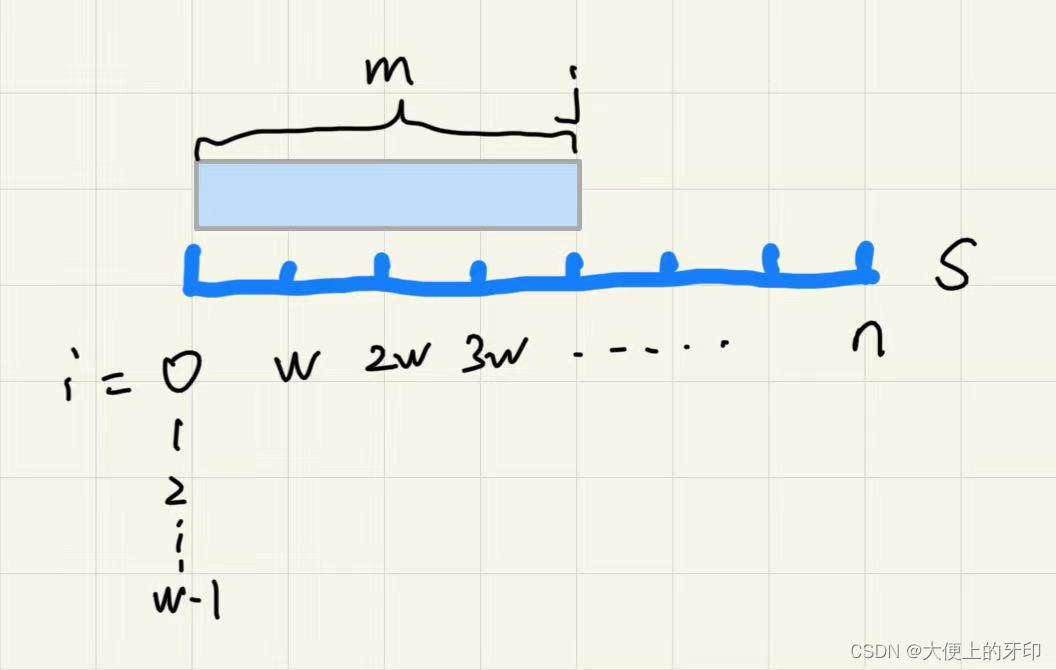
④设
m
a
p
\rm map
map 类型的
t
o
t
\rm tot
tot ,用来维护
w
o
r
d
s
words
words 里面的单词所对应的数量。
在每一个组中,设
m
a
p
\rm map
map 类型的
w
d
\rm wd
wd ,用来维护窗口内每个单词所对应的数量。
c
n
t
\rm cnt
cnt 表示两个集合中同时存在的单词的数量
时间复杂度:
对每个视作独立元素做滑动窗口,
n
w
\rm \frac{n}{w}
wn 次滑动窗口移动,每次移动加一个元素,减一个元素,一共有
w
\rm w
w 组,时间复杂度为
O
(
n
)
O(n)
O(n).
c++:
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> res;
if(words.empty()) return res;
int n = s.size(),m = words.size(),w = words[0].size();
unordered_map<string,int> tot;
for(auto& word : words) tot[word] ++;
for(int i = 0;i < w;i++)
{
int cnt = 0;
unordered_map<string,int> wd;
for(int j = i;j + w <= n;j += w)
{
if(j >= i + m * w)//若超出滑动窗口的长度,则将以j结尾的窗口的前一个单词排出
{
auto word = s.substr(j - m * w,w);
wd[word]--;
//剔除的该单词在滑动窗口集合的数量小于words里面单词的数量,说明匹配的数量减少了
if(wd[word] < tot[word]) cnt--;
}
auto word = s.substr(j,w);
wd[word]++;
//增加的单词在滑动窗口集合的数量增加之后依然没有超过words里单词的数量,说明满足条件的匹配的数量增加了
if(wd[word] <= tot[word]) cnt++;
if(cnt == m) res.push_back(j - (m - 1) * w);//当相应单词匹配的数量为m时,即匹配了words里所有的单词,则将滑动窗口起点加入答案。
}
}
return res;
}
};